Expectation Constructs: The Missing Primitive in Agentic AI
· 6 min read
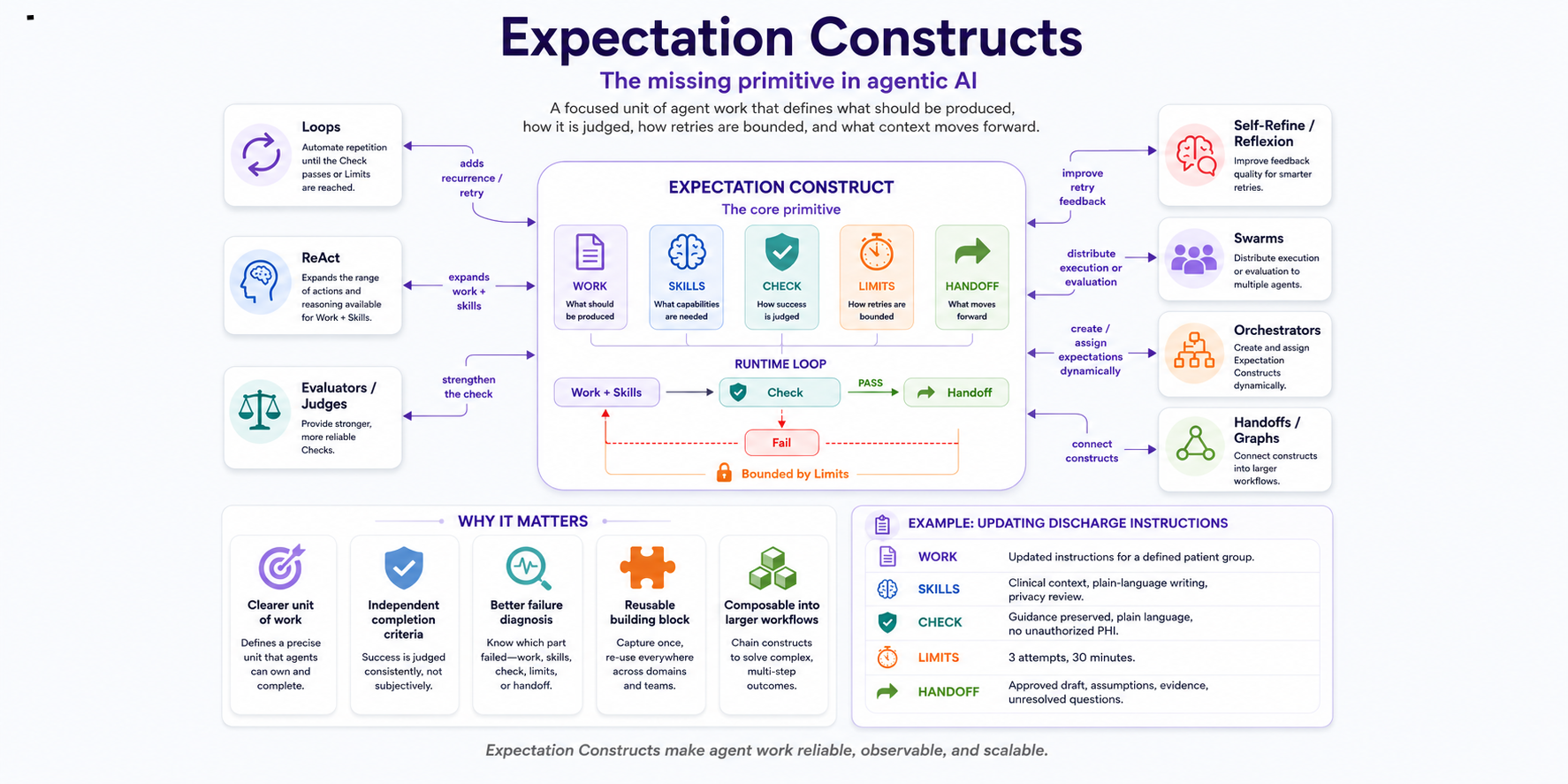
I have built and reviewed enough agentic systems to notice a recurring gap. We have plenty of patterns for how an agent thinks and acts—ReAct, reflection, evaluators, swarms, orchestrators. What we don't have is a clean, shared unit of work that ties those patterns together. When an agent fails, the honest answer to "which part broke?" is usually a shrug. We rerun the whole thing and hope.
That gap is expensive. Without a defined unit of work, you can't judge success consistently, you can't bound retries, and you can't tell whether the agent produced the wrong thing or was judged by the wrong standard. You end up debugging vibes.