Recursive Language Models on AWS with Strands Agents
Introduction
Modern large language models face a fundamental limitation: context windows. While frontier models now reach 1 million tokens (Nova Premier, Claude Sonnet 4.5), workloads analyzing entire codebases, document collections, or multi-hour conversations can easily exceed 10 million tokens—far beyond any single model's capacity.
This post demonstrates Recursive Language Models (RLMs), an inference strategy from MIT CSAIL research that enables scaling to inputs far beyond context windows. What makes this implementation special: Strands Agents and Amazon Bedrock AgentCore reduce what could be weeks of glue code and deployment work to just a few hours of development.
What Are Recursive Language Models?
Traditional approaches to long contexts use summarization or RAG. These struggle with information-dense tasks requiring examination of the full input.
Recursive Language Models are an inference pattern for handling inputs far larger than any model context window. Instead of stuffing the entire dataset into the prompt, the full context lives outside the model as an external context buffer (a Python variable). The model then generates code to search, filter, and chunk the context, and uses recursive sub-calls on only the relevant pieces. Finally, results are aggregated through deterministic code rather than attention over the full input.
This approach is especially effective for tasks like "find all occurrences," "count all items," or "extract all endpoints," where missing even one chunk causes incorrect results.
In our implementation, recursion depth is 1: the root model uses sub-calls to smaller models, and aggregation happens in code (not through nested RLMs).
RLM in Action: Minimal Pattern
# Context lives outside the model as a Python variable
context = load_large_codebase() # can exceed model context windows by 100x+
# Model writes code to probe and filter
api_files = search(context, pattern=r"@app\.route")
# Recursive sub-calls on filtered chunks
endpoints = []
for file in api_files:
result = llm_query(f"Extract endpoint info from:\n{file}")
endpoints.append(result)
# Deterministic aggregation
return aggregate(endpoints)
RLM vs RAG: When to Use Each
| Scenario | RAG | RLM |
|---|---|---|
| Known query upfront | ✅ Efficient retrieval | ⚠️ Overkill |
| "Find all" / "Count all" | ❌ May miss chunks | ✅ Exhaustive coverage |
| Relevance-based QA | ✅ Fast, targeted | ⚠️ Slower |
| Multi-step reasoning over full context | ❌ Limited by retrieval | ✅ Code-driven exploration |
RAG struggles when: you don't know what to retrieve upfront, when correctness depends on coverage (not relevance), or when you need "verify-all" guarantees.
Research Results
The MIT paper demonstrates RLMs:
- Successfully handle inputs up to 100x beyond model context windows
- Outperform base LLMs and common long-context scaffolds on long-context retrieval benchmarks
- Scale costs with task complexity, not input size
Note: Performance examples in this post are illustrative. Actual results vary by model, task complexity, and context structure.
Why Strands + AgentCore Makes This Easy
Building RLMs from scratch requires weeks of work: agent loop orchestration, REPL sandboxing, model invocation logic, deployment infrastructure, scaling configuration, and observability. Strands Agents and Amazon Bedrock AgentCore eliminate this complexity.
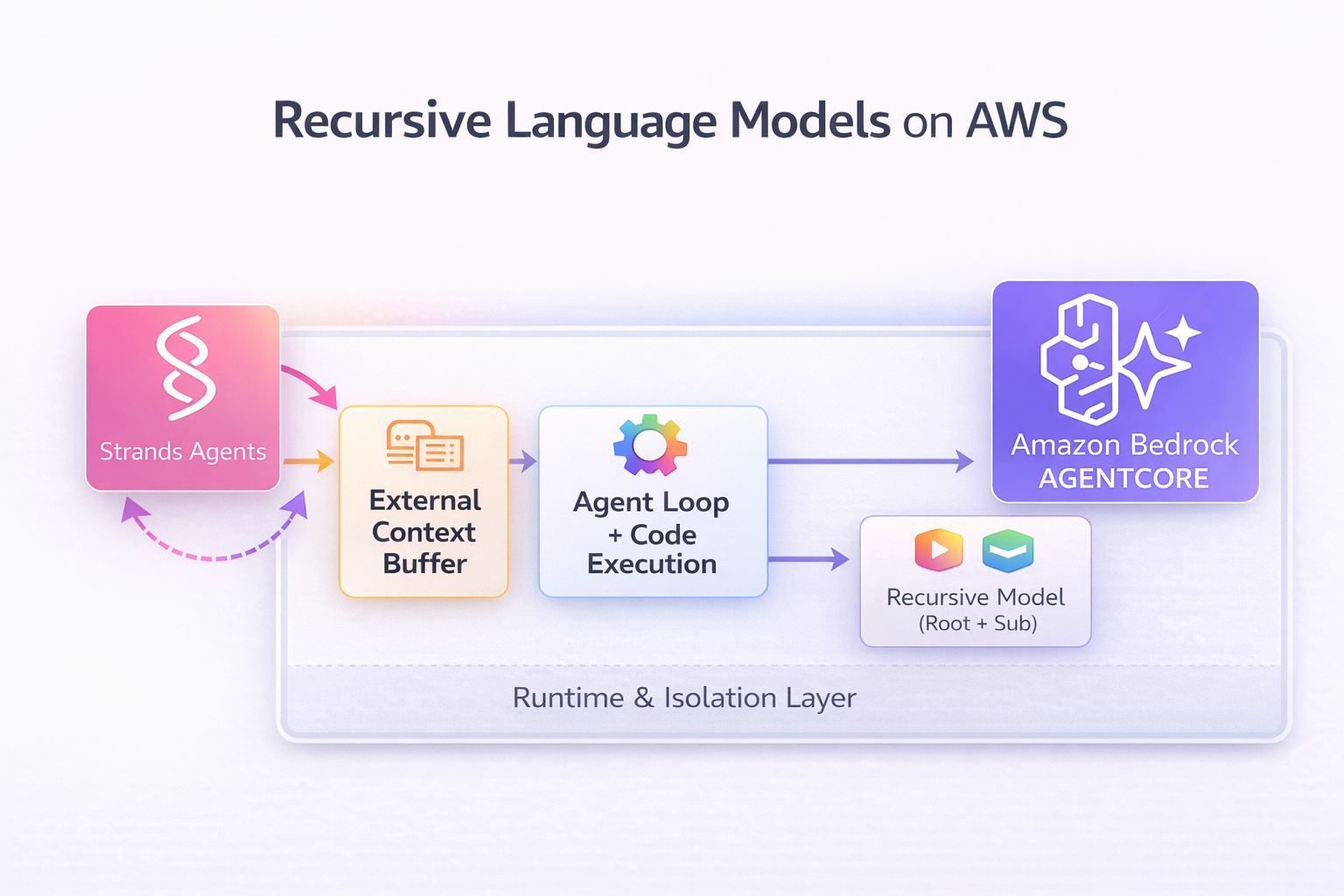
Architecture Overview
RLM implementation using Strands Agents and Amazon Bedrock AgentCore
The architecture shows the complete flow from user query to final answer:
Strands Agents: Orchestration Made Simple
Strands Agents is an open-source Python SDK for building AI agents. It provides:
- Agent loop orchestration - Handles iterative LLM → code execution → LLM cycles automatically
- Tool calling - Built-in Python REPL tool with output management
- Model integration - Native Amazon Bedrock support with streaming
- State management - Tracks conversation history and execution context
Impact: What would take weeks of infrastructure code becomes ~200 lines.
Amazon Bedrock AgentCore: Deployment Without the Pain
Amazon Bedrock AgentCore provides serverless runtime for AI agents:
- Long-running execution - 15-minute idle timeout when not processing (not a max runtime limit)
- Automatic scaling - Handles concurrent requests without capacity planning
- Session isolation - Each invocation gets isolated environment
- ARM64 optimization - AWS Graviton processors for cost efficiency
- Built-in observability - Amazon CloudWatch logs and metrics
Impact: Deployment is a standard CDK workflow, and invocation happens via the AgentCore Runtime API. RLM experiments that take 5+ minutes run without timeout issues. Safety limits (max sub-calls, output buffer) prevent runaway execution.
Cost Intuition
In practice, the root model spends tokens on planning and code generation, while sub-calls only process filtered slices of the context. This makes total token usage closer to "work performed" rather than "data size"—often landing closer to planning plus the slices you inspect (for example, tens to a few hundred thousand tokens for many workloads, depending on how much content is actually analyzed).
Amazon Bedrock: Model Choice
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, OpenAI, and Amazon through a single API. This model choice is critical for RLM implementations—different tasks benefit from different model strengths in reasoning, code generation, and cost efficiency.
Following the MIT paper's two-model approach, we use a root model for orchestration and a smaller model for sub-calls:
Supported Root Models:
- Amazon Nova Pro - 300K context, strong reasoning
- Claude 4.5 Sonnet - 200K context (1M beta), excellent code generation
- Claude 4.5 Opus - 200K context, frontier performance
- GPT-OSS 120B - 128K context, open-source option
Supported Sub-Call Models:
- Amazon Nova Micro - 128K context, optimized for speed
- Claude 4.5 Haiku - Fast, cost-efficient
- Amazon Nova Lite - Balanced performance
This two-tier approach balances capability and efficiency: a powerful model for strategy, a fast model for execution. Our implementation is model-agnostic—swap models via configuration without code changes.
How It Works
REPL Environment
The core innovation is loading the entire input context as an external context buffer (Python variable) accessible to the LLM. The environment provides:
contextvariable containing the full inputllm_query(prompt)function for recursive sub-LM calls- Standard Python libraries for text processing (regex, string manipulation)
- Isolated execution preventing access to system resources
The LLM writes Python code to interact with this environment, executing operations like regex searches, chunking, and filtering without loading the entire context into its neural network.
System Prompt Design
Based on MIT paper Appendix D, the system prompt is minimal and example-driven:
Core Instructions:
- Context is available as a Python variable in REPL, not in the prompt
- Use code to probe, filter, and chunk the context
- Make recursive
llm_query()calls on filtered chunks - Return final answer directly (no special format required)
Example Strategies:
- Regex filtering: Search for keywords without reading entire context
- Uniform chunking: Split into equal-sized pieces for parallel processing
- Semantic chunking: Use document structure (headers, file boundaries)
Example Pattern:
# Search in chunks
chunk_size = 50000 # ~12.5K tokens
for i in range(0, len(context), chunk_size):
chunk = context[i:i+chunk_size]
result = llm_query(f"Find the magic number in: {chunk}")
print(result)
The prompt avoids prescriptive "ALWAYS/NEVER" rules, letting models develop their own strategies.
Agent Loop
The Strands Agent orchestrates iterative REPL interaction:
- Root LM receives query and context metadata (length, structure)
- Root LM generates Python code to execute in REPL
- Code executes, output returned (truncated to prevent overflow)
- Root LM sees output, decides to continue or return answer
- Loop continues until answer provided or timeout
This iterative process allows the model to refine its approach based on execution feedback.
Asynchronous Processing
All experiments run asynchronously by default:
- Immediate response with task ID and session ID
- Client polls for results (no timeout issues)
- Tasks can run for minutes or hours
- Results automatically saved to Amazon S3 with full metadata
- 15-minute idle timeout only applies when NOT processing
This enables long-running RLM tasks without connection timeouts.
Recursive Sub-Calls
The llm_query() function enables decomposition:
- Sub-calls use smaller model (Amazon Nova Micro) with smaller context
- Each sub-call is independent (no shared state except via code variables)
- Sub-calls can be batched in code (process multiple chunks in loop)
- Results stored in Python variables for aggregation
The paper uses max recursion depth of 1 (sub-calls are base LLMs, not RLMs).
Deployment
AWS CDK deploys the RLM agent to AgentCore Runtime:
- Build ARM64 Docker image with Strands Agent code
- Create IAM role with Bedrock, S3, and CloudWatch permissions
- Deploy datasets (TREC, BrowseComp+, CodeQA) to S3 bucket
- Configure CloudWatch log group for traces
- Deploy AgentCore Runtime with container image
AgentCore handles scaling, versioning, and observability automatically. Datasets are uploaded during cdk deploy and downloaded by the runtime on-demand.
Example: Analyzing Large Codebases
Task: Identify all API endpoints and their authentication requirements in a codebase with hundreds of files.
Traditional Approach Limitations:
- Direct LLM call: May exceed context window
- RAG: May miss endpoints, requires good chunking strategy upfront
- Manual analysis: Time-consuming, error-prone
RLM Approach:
- Probe: Check total size, identify file boundaries
- Filter: Use regex to find files with route decorators (
@app.route,@api.route) - Analyze: Make sub-LM calls on each API file to extract endpoint details
- Aggregate: Combine results into structured summary
Outcome:
- Processes codebases beyond single model context limits
- Identifies all API endpoints systematically
- Extracts authentication requirements for each
- Completes in minutes with minimal sub-calls
Benchmarks and Findings
Performance on Long-Context Tasks
We evaluated RLM on benchmarks using real-world datasets (TREC, Tevatron BrowseComp+, LongBench-v2) deployed to S3.
| Test | Context Size | Task | Dataset Source |
|---|---|---|---|
| OOLONG | 5,452 TREC entries | Count label frequencies | TREC coarse dataset |
| OOLONG-Pairs | 5,452 TREC entries | Find HUM/LOC pairs | TREC coarse dataset |
| BrowseComp-1K | 1,000 documents | Answer research query | Tevatron BrowseComp+ |
| CodeQA | Multi-file repos | Multi-choice reasoning | LongBench-v2 Code |
Key Findings:
Accuracy for Retrieval Tasks: Code-based counting and searching reduces hallucinations for tasks requiring exact matches. Direct model calls often produce inconsistent results on the same input.
Real Datasets: All benchmarks use production datasets (~216MB total) deployed to S3 and loaded at runtime, simulating real-world information retrieval scenarios.
Async Execution: All tests run asynchronously with results saved to S3, enabling long-running tasks without timeout issues.
Emergent Behaviors
RLM trajectories showed interesting patterns:
- Regex filtering: Models searched for keywords without reading entire context
- Adaptive chunking: Adjusted chunk sizes based on task complexity
- Answer verification: Made additional sub-calls to validate results
- Strategic decisions: Chose between "process all" vs "filter then process" strategies
Limitations
- Async-first design: All experiments run asynchronously; synchronous mode available but not recommended for long tasks
- Model-specific behavior: Different models show varying chunking strategies and sub-call patterns
- Sub-call limits: Max 50 sub-calls prevents runaway execution but may limit very complex tasks
- Debugging complexity: Full trajectory examination needed via CloudWatch logs
- Dataset size: Real datasets (TREC, BrowseComp+, CodeQA) are large files (~216MB total) deployed to S3
When to Use RLMs
Ideal for:
- Information-dense aggregation across entire datasets
- Large codebase analysis (patterns, security, dependencies)
- Multi-document reasoning requiring synthesis
- Contexts beyond model limits
Use alternatives for:
- Single-document QA within context window (direct calls)
- Sparse retrieval (RAG more efficient)
- Real-time requirements (RLM takes seconds to minutes)
- Simple extraction (regex/parsing sufficient)
Observability
AgentCore provides CloudWatch integration for monitoring RLM trajectories:
Enable Transaction Search: One-time setup to send X-Ray traces to CloudWatch Logs for GenAI Observability dashboard.
View Traces: CloudWatch → GenAI Observability shows:
- Complete RLM trajectories (each REPL iteration)
- Sub-LM call patterns (count, timing, token usage)
- Token efficiency (processed vs. context size)
- Execution time breakdown
Key Metrics:
- Trajectory length: Number of REPL iterations (target: <20)
- Sub-call count: Recursive invocations (target: <30)
- Token efficiency: % of context actually processed
- Success rate: FINAL() vs. timeouts
Best Practices
System Prompt Design
- Keep it minimal and example-driven (following MIT paper)
- Show chunking strategies, don't prescribe them
- Let models develop their own approaches
- Emphasize
print()for code outputs
Context Generation
- Real benchmarks: Deploy production datasets (TREC, BrowseComp+, CodeQA) to S3 (~216MB total)
- Runtime downloads datasets on-demand from S3
- Makes benchmarks representative of real-world scenarios
Safety
- Isolate REPL execution (no file system access)
- Limit output buffer (last 100 lines)
- Set max recursion depth (depth=1)
- Max sub-calls limit (50 in our implementation)
Error Handling
- Return exceptions to root model
- Retry transient Bedrock errors
- Use async mode for long-running tasks
- Log all trajectories to CloudWatch
Getting Started
The complete implementation is available on GitHub with interactive CLI, deployment automation, and benchmark suite.
Quick Start
# Clone repository
git clone https://github.com/manu-mishra/RLMWithStrands
cd RLMWithStrands
# Deploy to AWS
cd infra
cdk deploy
# Run benchmarks
python runexperiments
# Interactive menu:
# 1. Run Benchmarks → Async (default) → Select model → Run All
# 2. Results saved to S3 automatically
Future Directions
- Deeper recursion: Allow sub-RLMs (depth=2+) for hierarchical decomposition
- Parallel sub-calls: Execute multiple chunks simultaneously to reduce latency
- Multi-modal RLMs: Extend to images, audio, video processing
- Fine-tuned models: Train on RLM trajectories to improve chunking efficiency
- Streaming results: Return partial answers as they're computed
Conclusion
Recursive Language Models (RLMs) enable processing inputs far beyond model context windows by treating the dataset as an external context buffer and using code to probe, filter, and recursively analyze only the relevant parts. By combining Strands Agents (agent loop + REPL orchestration) with Amazon Bedrock AgentCore (serverless runtime + observability), you can go from research idea to working implementation in hours instead of weeks.
This approach is especially useful for "find all / count all / verify all" workloads such as large codebase analysis, multi-document synthesis, and long-horizon agent workflows—where traditional long-context prompting or retrieval-only strategies can miss critical details.
Key Benefits:
- Model choice - Root + sub-call model flexibility (Nova, Claude, GPT-OSS)
- Serverless runtime - AgentCore handles scaling and deployment
- Observability - CloudWatch GenAI dashboard with full trajectories
- Async execution + safety limits - Long-running tasks with guardrails
Resources
- GitHub: github.com/manu-mishra/RLMWithStrands
- Research Paper: Recursive Language Models (arXiv:2512.24601)
- Strands Agents: github.com/awslabs/strands-agents
- Amazon Bedrock AgentCore: aws.amazon.com/bedrock/agentcore
- Amazon Bedrock: aws.amazon.com/bedrock
- AWS CDK: docs.aws.amazon.com/cdk
Tags: #AmazonBedrock #GenerativeAI #AgentCore #StrandsAgents #MachineLearning #AWS