Recursive Language Models on AWS with Strands Agents
· 12 min read
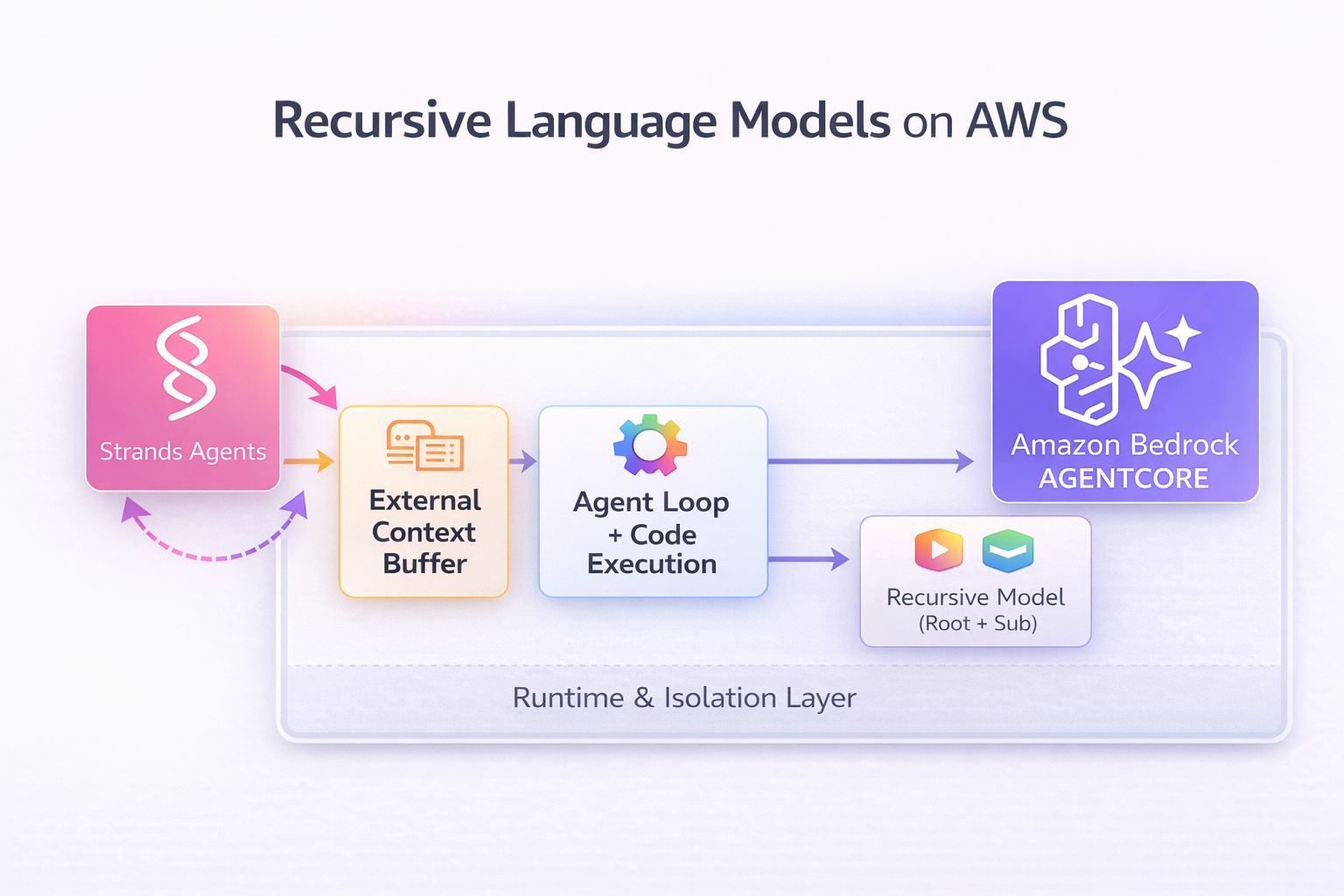
Introduction
Modern large language models face a fundamental limitation: context windows. While frontier models now reach 1 million tokens (Nova Premier, Claude Sonnet 4.5), workloads analyzing entire codebases, document collections, or multi-hour conversations can easily exceed 10 million tokens—far beyond any single model's capacity.
This post demonstrates Recursive Language Models (RLMs), an inference strategy from MIT CSAIL research that enables scaling to inputs far beyond context windows. What makes this implementation special: Strands Agents and Amazon Bedrock AgentCore reduce what could be weeks of glue code and deployment work to just a few hours of development.

