Serverless Streaming Analytics with S3 Tables & Firehose
Introduction
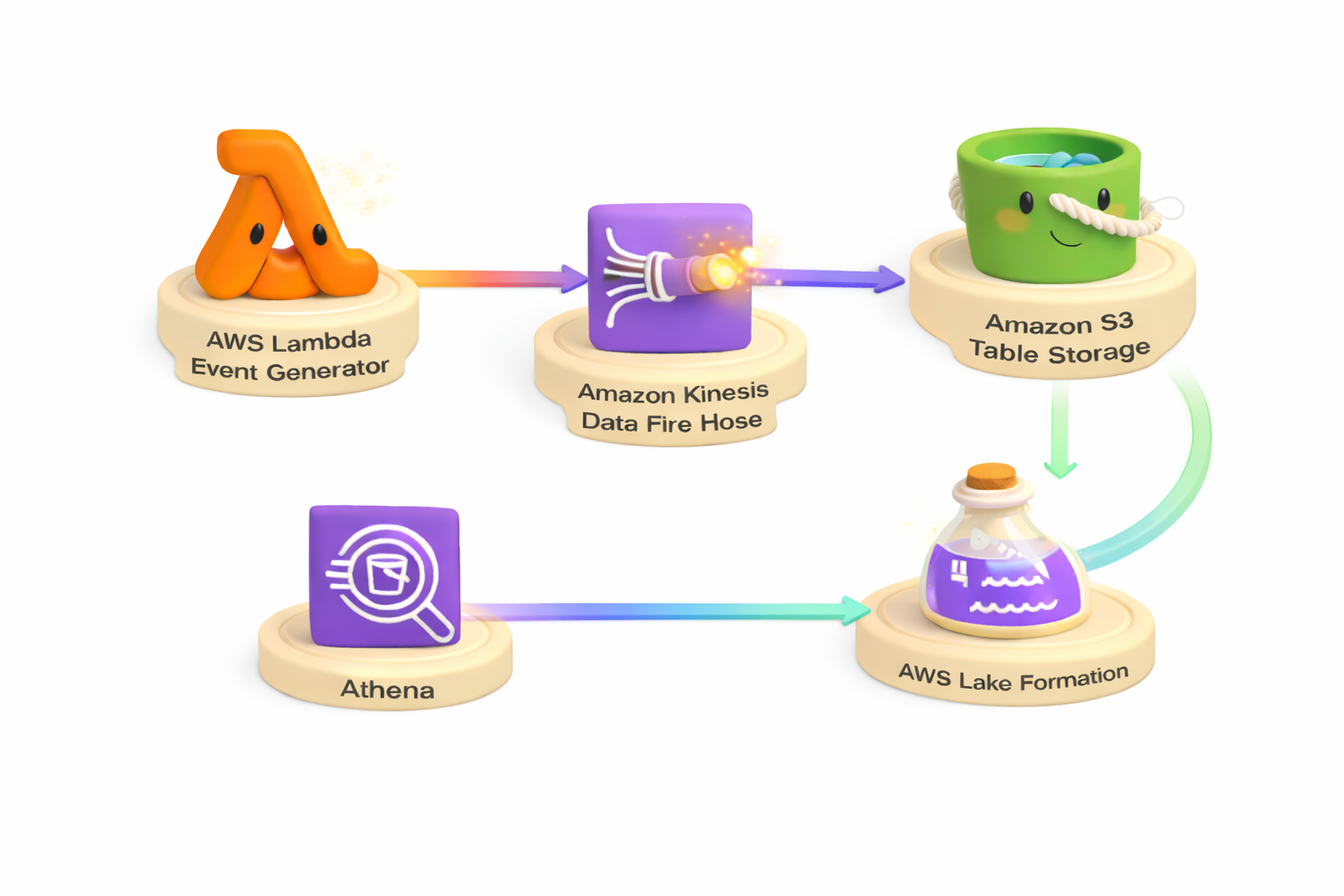
Modern businesses need to analyze streaming data in real-time to make faster decisions. Whether it's monitoring IoT sensors, tracking user behavior, or processing financial transactions, the ability to query fresh data immediately is critical. However, building a streaming analytics pipeline traditionally requires managing complex infrastructure and dealing with data format conversions.
This solution shows how to build a serverless real-time streaming analytics pipeline using Amazon S3 Tables and Amazon Kinesis Data Firehose. By combining streaming ingestion with Apache Iceberg's analytics-optimized format, you can query data within minutes of generation—without managing any servers or data transformation jobs.
GitHub Repository: https://github.com/manu-mishra/s3table-firehose-lambda-terraform-demo

